







Proč QUERY? Protože je to jedna z nejvýkonnějších funkcí Google Sheets s širokou škálou funkcionalit, které lze libovolně kombinovat a měnit. Pokud znáte alespoň základní funkce QUERY, budete s ní schopni pokrýt většinu interakce s tabulkami. Budete také optimalizovat a automatizovat procesy a zbavíte se ručního zpracování dat a sestav.
Z pohledu syntaxe se QUERY podobá dotazovacímu jazyku SQL a je zde opravdu prostor pro experimentování – může být jednoduchá nebo obsahovat více než 10 řádků.
V tomto tutoriálu si za příklad vezmeme filmová data z Wikipedie a prozkoumáme jejich různé využití pomocí QUERY. Budu nabízet řešení, která osobně používám při své práci.
Můžete například vyfiltrovat data nebo vytvořit dynamický rozbalovací seznam, který seřadí údaje podle statického nebo dynamického data, názvu nebo omezujících dat (režisér = Kevin Smith). V takovém případě se bude hodit funkce QUERY. Konečný výsledek naší práce najdete zde (tento soubor obsahuje všechny příklady dalších vzorců). Jdeme na to!


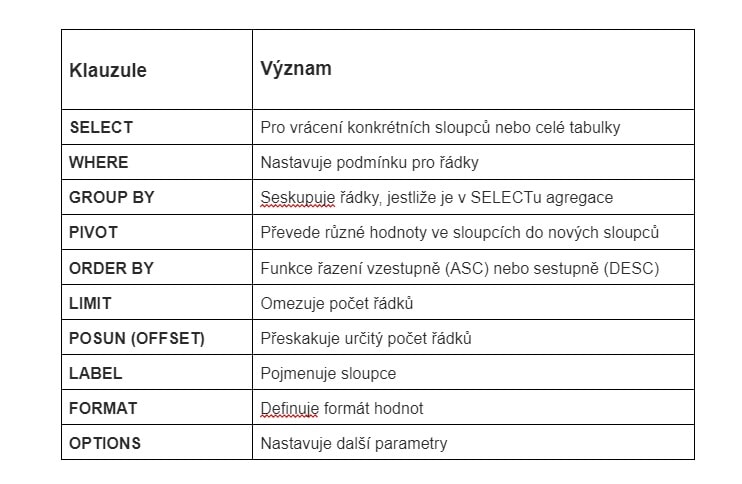
Obsah dotazu QUERY:
- Základní funkce, struktury a syntaxe
- Import vzorců – například stažení tabulky z Wikipedie nebo import dat z jiné tabulky
- ORDER BY – řazení podle hodnoty
- LIMIT/ OFFSET – zobrazení 5 nejlepších hodnot pro vaši tabulku
- Přejmenování sloupce tabulky pomocí funkce LABEL
- GROUP BY – seskupování a agregace dat (sčítání, násobení)
1. Základní funkce, konstrukce a syntaxe QUERY
Základní syntaxe vypadá takto:
=QUERY(rozsah dat; "SELECT (volaná a klíčová slova)")
Standardní volání QUERY vypadá takto:
=QUERY(A:B; "SELECT * ")
kde A:B je rozsah a "*" je volání pro všechny sloupce tabulky. V našem případě se SELECT * rovná SELECT A, B – to znamená všechny sloupce z našeho rozsahu.
Při volání importních dotazů se budou sloupce nazývat Col1 a Col2 namísto A a B. Klíčová slova můžeme zapsat v každém případě – můžeme použít QUERY, nebo query, SELECT, nebo select. Co se však týče hodnot, podmínky jsou jasné: pouze velká písmena A a B nebo pouze Col1 a Col2.
Pro omezení sloupců, například potřebujeme pouze sloupec A, by dotaz vypadal takto:
=QUERY(A:B; “SELECT А”)
Takto to vypadá:
A konečné zobrazení, po stisknutí klávesy Enter, vypadá takhle:
Po zadání SELECT * nebo zadání požadovaných sloupců pomocí SELECT A nebo SELECT Col1 můžete začít zadávat další klíčová slova.
Vzorec bude fungovat i bez nich. Další klíče jsou další aspekty, které rozšiřují vaše možnosti.
Můžete je používat samostatně nebo je můžete kombinovat. Záleží však na pořadí. Pokud nejprve použijete ORDER BY a až poté WHERE, aplikace Google Sheets to označí jako chybu a vzorec nebude fungovat.
2. Vzorce pro import v QUERY
Pokud potřebujete zobrazit tabulku z jiného zdroje nebo jiné tabulky, funkce QUERY podporuje standardní webové funkce tabulky Google (obrázek převzatý z nápovědy Google):

Nejběžnější z nich je IMPORTRANGE, která umožňuje importovat data z jiné tabulky Google.
Importní vzorce se nacházejí v bloku QUERY "range".
Syntaxe:
IMPORTRANGE = IMPORTRANGE("kód odkazu"; " range")
Kde kód odkazu je:

(Není potřeba už kopírovat "kód odkazu", ale může se tam dát odkaz na celou URL toho Google Sheets. Pozn. red.)
A range je název listu, ze kterého budete importovat, následovaný vykřičníkem a sloupci bez mezer, například:
Basics!A:B - pracovní list s názvem Basics, sloupce A až B.
Příklad konečného tvaru vzorce:
=QUERY(IMPORTRANGE("1awflL8d91pZvUvese4f8MRI_U32RiaBFRw5uvvAJefE"; "Basics!A:B"); "SELECT *")
Důležité: po zapsání bude vzorec zvýrazněn červenou barvou.

Tak by to mělo být. Stiskněte Enter a podívejte se na zprávu:
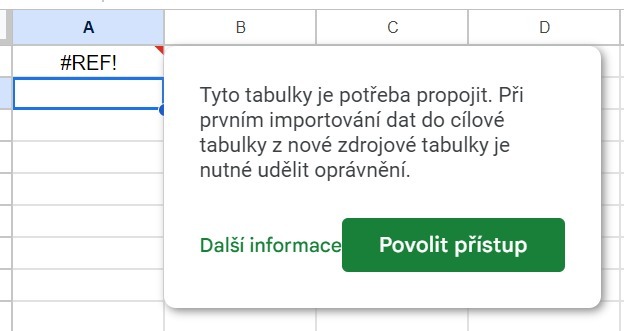
Klikněte na „Povolit přístup“ a dostanete importovanou tabulku.
Veškerý obsah v užitečném formátu. Rozhovory, články, life hacky a tipy ze světa businessu i korporátů na našem LinkedIn profilu.
Pojďte se připojit!

Jestliže chcete použít více tabulek nebo rozsahů, můžete tak učinit pomocí ARRAYFORMULA. Nezapomeňte však, že pokud k tabulkám neotevřete přístup, nebudou k dispozici žádná data. Při použití vzorce pole se takové chybové hlášení neobjeví, data se prostě nezobrazí. Je třeba otevřít přístup ke každé tabulce zvlášť a pak je seskupit do 1 rozsahu.
Vzorec IMPORTHTML je podobný vzorci IMPORTRANGE. Zde je příklad, který v článku použijeme:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/List_of_horror_films_of_2023";"Table"); "Select * ")
Jak vidíte, rozdíl je v tom, že zde vkládáme celý odkaz na zdroj, ze kterého získáme požadovanou tabulku. Odkaz můžete zkopírovat ze vzorce a zobrazit jeho součásti.
* Výše v popisu QUERY jsem poznamenala, že při použití standardního rozsahu
=QUERY(A:D; “SELECT А, C, D”)
použijete název sloupce, tedy konkrétní písmeno – A, C, D.
Pokud použijete import, pak místo A bude Col1, místo C bude Col3 a místo D bude Col4. A nezapomeňte na velikost písmen.
Zadejte
=QUERY(IMPORTRANGE("1awflL8d91pZvUvese4f8MRI_U32RiaBFRw5uvvAJefE";"Basics!A:B"); "SELECT A")
Zobrazí se chyba.
Zadejte
=QUERY(IMPORTRANGE("1awflL8d91pZvUvese4f8MRI_U32RiaBFRw5uvvAJefE";"Basics!A:B"); "SELECT col1")
nebo
=QUERY(IMPORTRANGE("1awflL8d91pZvUvese4f8MRI_U32RiaBFRw5uvvAJefE";"Basics!A:B"); "SELECT COL1")
Zobrazí se chyba.
Správná varianta:
=QUERY(IMPORTRANGE("1awflL8d91pZvUvese4f8MRI_U32RiaBFRw5uvvAJefE";"Basics!A:B"); "SELECT Col1")
* Výše jsem se zmínila o importu z více tabulek. Hlavní podmínkou je, že tabulky musí mít podobnou strukturu.
Cílem je vytvořit 1 sdílenou tabulku z table1, table2, table3.
Pro každou tabulku vytvoříme samostatný import pro udělení přístupu a stejně jako výše klikneme na tlačítko „Povolit přístup“.
Poté vše uzavřeme do kulatých závorek a získáme výsledek.
Takto vypadá vzorec:
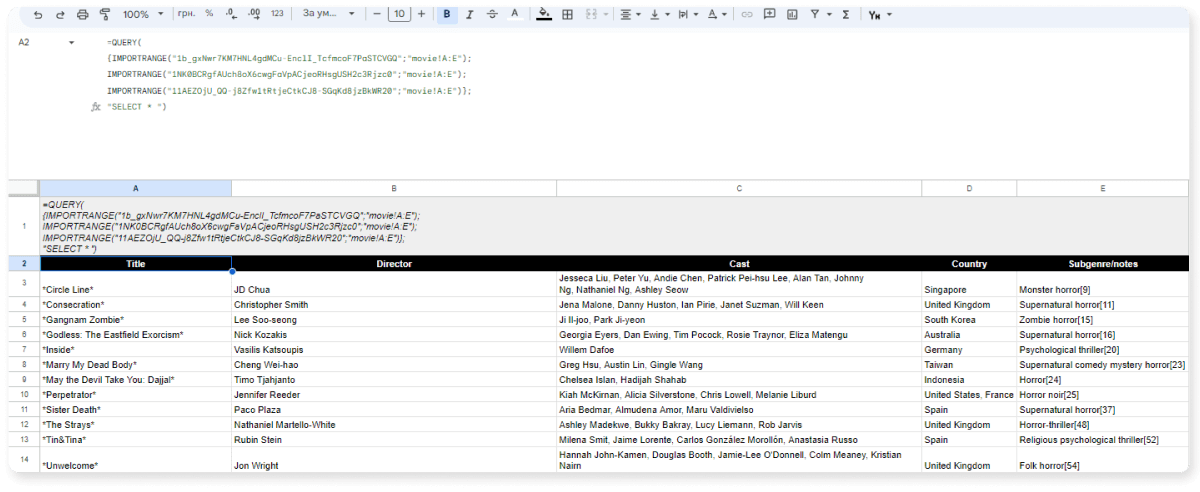
=QUERY(
{IMPORTRANGE("1b_gxNwr7KM7HNL4gdMCu-EnclI_TcfmcoF7PaSTCVGQ";"movie!A:E");
IMPORTRANGE("1NK0BCRgfAUch8oX6cwgFaVpACjeoRHsgUSH2c3Rjzc0";"movie!A:E");
IMPORTRANGE("11AEZOjU_QQ-j8Zfw1tRtjeCtkCJ8-SGqKd8jzBkWR20";"movie!A:E")};
"SELECT * ")
A takto vypadá tabulka:
3. Blok pro řazení tabulky podle kritérií (list ORDER BY naší tabulky)
Zde začneme od nejlepších filmů: 100 Years...100 Movies – 10th Anniversary Edition (zdroj Wikipedia). Ve svých tabulkách nemusíte používat další zdroj ani jinou tabulku. Rozsah může být podle vašeho uvážení libovolně široký.
Vezmeme tedy začátek vzorce z předchozího bloku:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select *")
Pomocí SELECT * jsme zobrazili všechna data a nyní je začneme třídit.
Máme:
- RANK (funkce) – pořadí ve formátu Text od 1. do 100. (není to číslo, protože na konci máme tečku)
- 10th anniversary list (2007) – název filmu v textovém formátu
- Režisér – režisér ve formátu Text
- Rok – ve formátu Číslo (všimněte si, že se nejedná o datum, ale o číslo – můžete jej zkusit převést na formát Datum na záložce Formát v záhlaví tabulkového procesoru Google a uvidíte, co se stane)
* případně pomocí následujícího vzorce =DATE(D3;1;1), kde D3= číslo „1941“ a „1“ a „1“ jsou čísla měsíce a dne, můžete převést náš rok ve formátu Číslo na Datum - Výrobní společnosti – firma, formát Text
- Změna od roku 1998 – počet změn ve formátu Číslo
Teď seřaďme naši tabulku podle sloupce Rok. To můžeme provést pomocí klauzule ORDER BY. Tato klauzule podporuje DESC pro sestupné řazení a ASC pro vzestupné řazení (používá se ve výchozím nastavení).
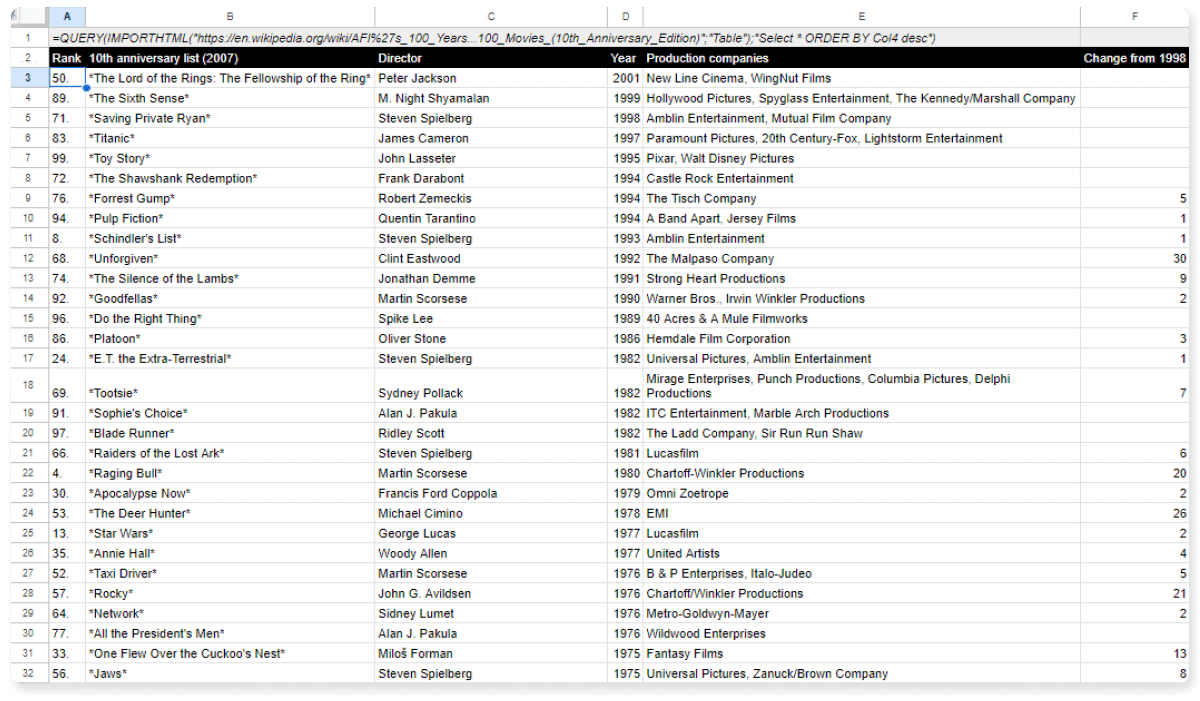
Cíl 1: Seřadit zadaný rozsah dat podle roku vzniku sestupně:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select * ORDER BY Col4 desc")
Cíl 2: Seřadit sestupně podle roku vzniku a vzestupně podle režiséra (nezapomeňte, že vzestupné pořadí, tj. ASC, se používá ve výchozím nastavení, takže to nemusíte psát).
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select * ORDER BY Col4 desc, Col3")
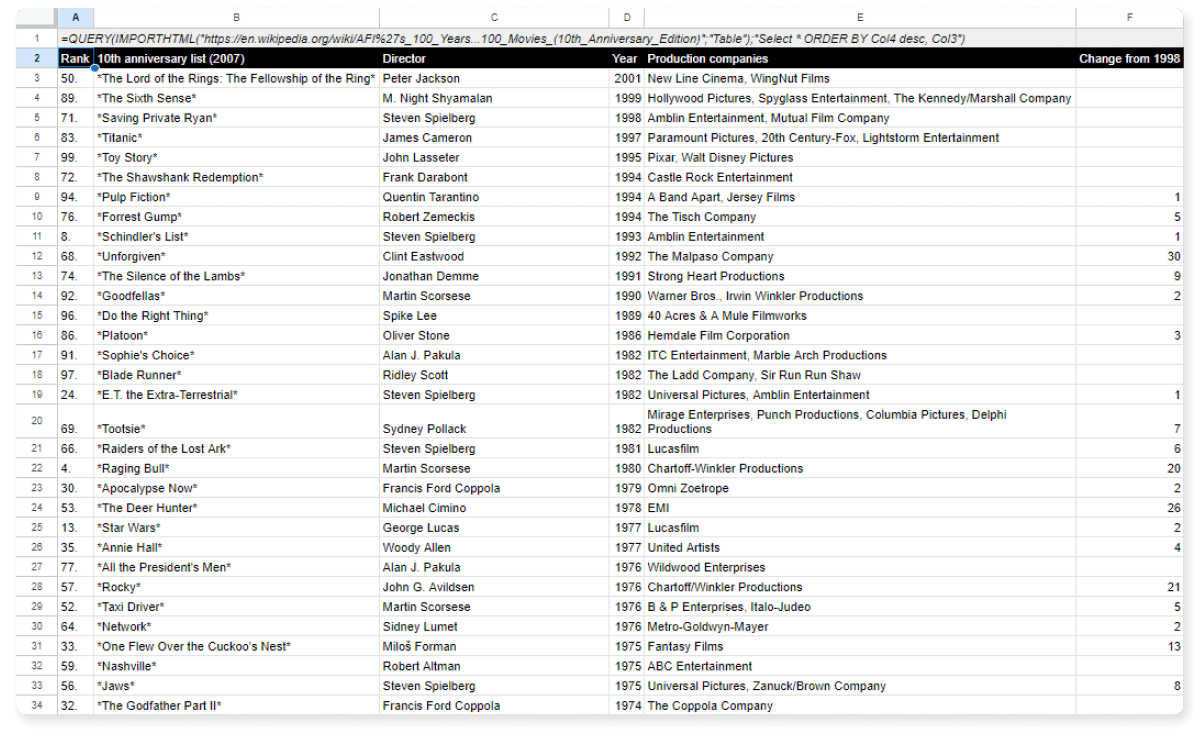
Jen jsme přidali čárku a doplnili, co jsme ještě potřebovali seřadit.
4. Funkce LIMIT/OFFSET v QUERY
I nadále používáme náš seznam 100 nejlepších filmů za posledních 100 let.
Připomínám, že náš základní vzorec vypadá takto:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select *")
- LIMIT – omezení počtu řádků. Mějte na paměti, že první řádek (záhlaví tabulky) se nezapočítává.
Zkuste vzorec nastavit takto a uvidíte, co se stane:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select * LIMIT 0")
A teď takto:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select * LIMIT 1")
- OFFSET – říká, že byste neměli počítat od prvního řádku, ale například od 3. řádku. Naše tabulka má sloupec Pořadí, takže sami vidíte výsledek, jak a co se zobrazí.
Vezměme si, že cílem je vypsat 2 řádky počínaje 4. řádkem (tj. limit 2 offset 3 – v tomto případě se třetí řádek nevypíše, offset 3 bude začínat od 4. řádku tabulky):
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");"Select * LIMIT 2 OFFSET 3")
A naše tabulka vypadá takto:

V našem případě je pro sestavení tabulky „Top 5 filmů“ vhodné použít kombinaci LIMIT + ORDER BY. To znamená, že seřadíme podle určitého parametru a zobrazíme první hodnoty.
Cíl: vypsat posledních 5 filmů z našeho seznamu.
Zde použijeme sestupné řazení pomocí ORDER BY a poté omezíme počet řádků pomocí LIMIT – náš vzorec bude vypadat takto:
=QUERY(
IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");
"SELECT *
ORDER BY Col4 DESC
LIMIT 5")
A tabulka vypadá takto:

5. Přejmenování sloupců pomocí funkce LABEL
Podívejme se na předchozí příklad. Jde o to, že QUERY nevytváří běžnou tabulku, ale celé pole. A pokud chcete změnit název sloupce, nemůžete ho jen tak ručně přepsat.
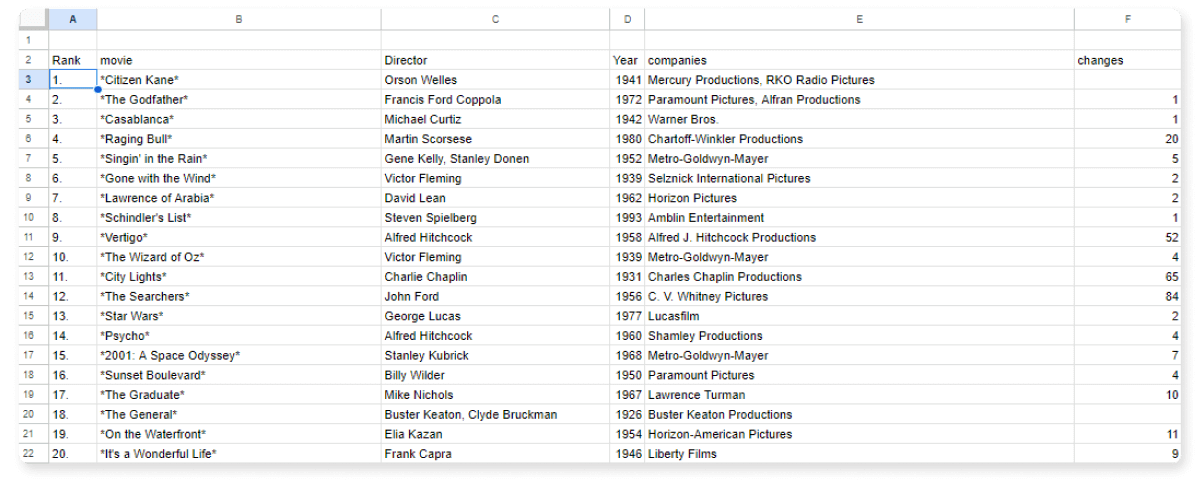
Náš název, 10th anniversary list (2007), je poměrně dlouhý, takže si vystačíme jen s filmem. Přepíšeme to: přidáme nový název a dostaneme chybu.

„Výsledek pole není rozšířen, jinak by přepsal data v B2.“
Odstraníme tedy název „film“ a na konec našeho vzorce přidáme LABEL Col2 "film".
Současně změníme Production companies na companies a Change z 1998 na changes.
Vzorec:
=QUERY(IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");
"SELECT *
LABEL Col2 'movie', Col5 'companies', Col6 'changes'")
Tabulka:
6. Funkce GROUP BY v QUERY
V této části se podíváme na seskupování dat po provedení agregace.
Máme například následující soubor dat:
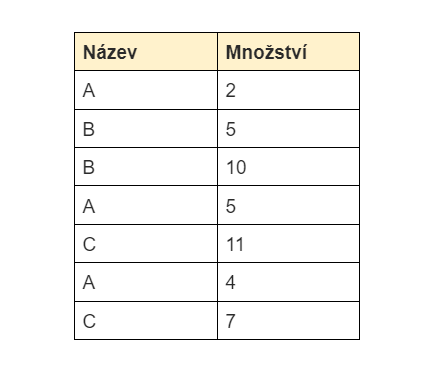
Naším cílem je vytisknout tabulku, která shrnuje údaje ze sloupce „Množství“ podle názvu:
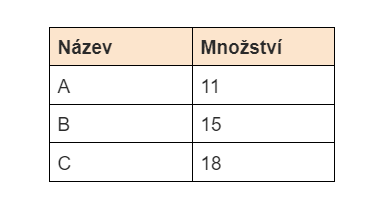
To znamená, že jsme sečetli řádky podle pole „Množství“ a napsali, že seskupení by mělo být podle parametru „Název“.
Z toho vyplývá, že GROUP BY nemá bez agregace smysl a agregace bez GROUP BY nefunguje.
Podporované agregační funkce:
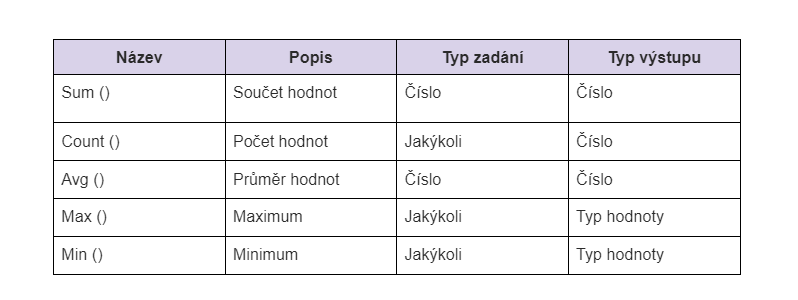
Z předchozího příkladu odvodíme vzorec z tabulky se sloupci „Název“ a „Množství“:
=QUERY(A:B;”Select A, sum(B), count(B), avg(B), max(B), min(B) GROUP BY A ")
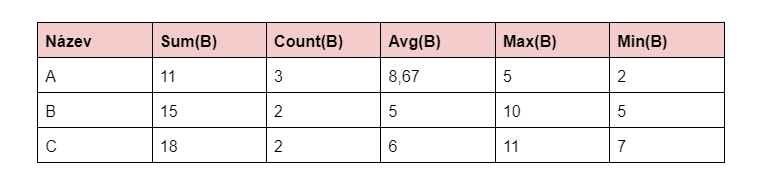
* V našem příkladu byly pouze 2 sloupce, z nichž 1 je agregovaný a druhý je seskupený. V jiné situaci, kdy máte například 10 sloupců a 1 z nich je agregovaný, budete muset seskupit podle všech ostatních 9 sloupců. Pokud jste se již touto cestou vydali, neměli byste nechat žádný sloupec neagregovaný nebo neseskupený.
Projděme si další příklad.
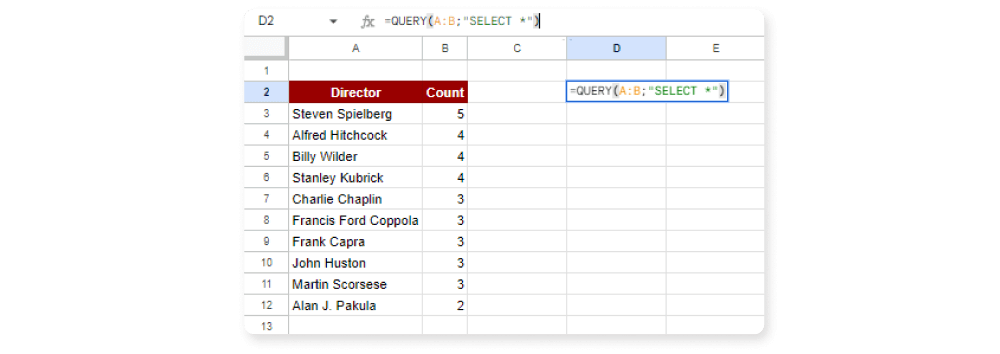
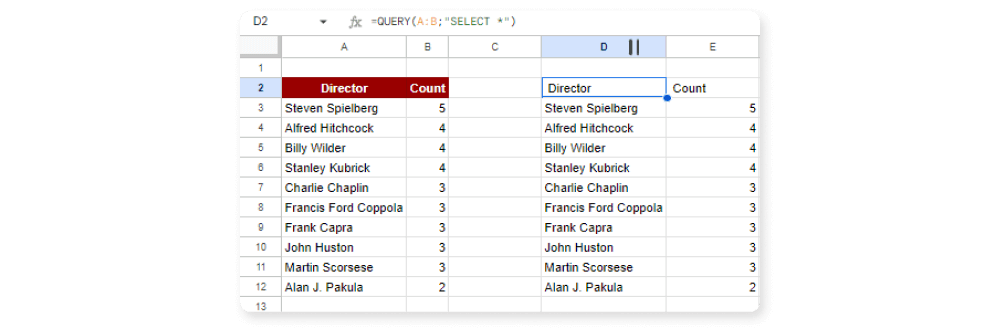
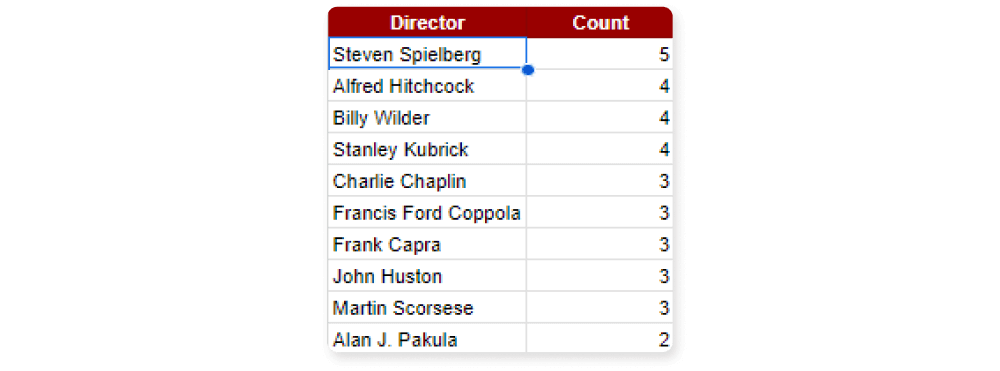
Cílem je vypsat 10 režisérů, jejichž filmy se v našem seznamu 100 nejlepších filmů za posledních 100 let objevily nejčastěji, a to v sestupném pořadí. Výstup by měl obsahovat 2 sloupce s názvy Director a Count:
=QUERY(
IMPORTHTML("https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies_(10th_Anniversary_Edition)";"Table");
"SELECT Col3, COUNT(Col3)
GROUP BY Col3
ORDER BY COUNT(Col3) DESC
LIMIT 10
LABEL Col3 'Director', COUNT(Col3) 'Count'
")
Výsledkem je následující tabulka.
Náš vzorec vypadá stále těžkopádněji. Abyste se v kódu neztratili, doporučuji jej rozdělit do samostatných bloků, aby vám hodnoty nezmizely. Odstavec ve vzorci vytvoříte stisknutím kláves Alt + Enter.
Stojí za zmínku, že symboly:
„+“ – sčítání
„-“ – odečítání
„/“ – dělení
„*“ – násobení
jsou podporovány a nespadají pod seskupování podle předchozí logiky, protože pracujeme s existujícím číslem v existující buňce.
To je pro dnešek vše. Plánujeme však druhou část průvodce, kde budeme rozebírat klauzuli WHERE a také hlavní chyby při práci s funkcí QUERY.

